[JAVA] 컬렉션과 스트림
컬렉션
- 여러 원소를 하나의 그룹으로 묶어 관리하기 위한 자료구조
- JSF(Java Collections Framework)
- 컬렉션을 일관된 방법으로 다루기 위한 통합 프레임워크
- 다양한 방식으로 저장, 정렬, 검색, 수정하는 도구를 제공
JSF의 인터페이스
- java.util 패키지에 포함되며 제네릭 타입
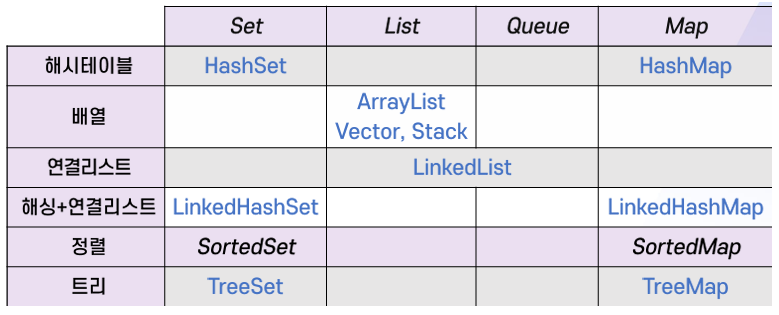
- Set: 데이터의 순서는 의미가 없으며 중복을 허용하지 않는 자료구조
- List: 중복을 허용하고 순서가 있는 자료구조
- Queue: List와 유사하나 원소의 삽입/삭제가 FIFO 방식임
- Map: 원소가
<key, value>형태이며 키는 유일해야 함
컬렉션 객체 선언
- 변수 선언은 해당 인터페이스 유형으로, 객체 생성은 인터페이스를 구현하는 클래스를 사용한다.
1
2
3
4
5
Set<Integer> set = new HashSet<>();
List<Integer> list = new ArrayList<>();
List<Integer> list = new LinkedList<>();
Queue<Integer> list = new LinkedList<>();
Map<String, Integer> list = new HashMap<>();
Collection<E> 인터페이스
- Set, List, Queue에서 공통으로 지원해야 하는 기능을 정의
원소 탐색 메소드
| 메소드 | 설명 |
|---|---|
| boolean contains(Object o) | 현재 컬렉션이 주어진 요소를 가지고 있으면 true를 리턴함 |
| boolean containsAll(Collection<?> c) | 현재 컬렉션에 주어진 컬렉션의 모든 요소를 가지고 있으면 true를 리턴함 |
| boolean isEmpty() | 현재 컬렉션이 빈 컬렉션이면 true를 리턴 |
원소의 삽입과 삭제 메소드
| 메소드 | 설명 |
|---|---|
| boolean add(E e) | 주어진 요소를 현재 컬렉션에 추가. 성공적으로 추가되면 true를 리턴함 |
| boolean addAll(Collection<? extends E> c) | 주어진 컬렉션의 모든 요소를 현재 컬렉션에 추가 |
| boolean remove(Object o) | 주어진 요소를 컬렉션에서 제거 |
| boolean removeAll(Collection<?> c) | 주어진 컬렉션에 포함된 모든 요소를 현재 컬렉션에서 제거 |
| boolean retainAll(Collection<?> c) | 현재 컬렉션의 요소 중, 주어진 컬렉션에 있는 요소만 남김 |
| void clear() | 컬렉션의 모든 요소를 제거하여 비움 |
기타 메소드
| 메소드 | 설명 |
|---|---|
| int size() | 현재 컬렉션에 포함된 요소의 개수를 리턴함 |
| int hashCode() | 현재 컬렉션의 해시 코드값을 리턴함 |
| Object[] toArray() | 현재 컬렉션을 객체의 배열로 변환하여 리턴함 |
| Iterator | Iterator 객체를 리턴함 |
| boolean equals(Object) | 두 컬렉션이 같은 요소를 같은 순서로 포함하면 true를 리턴함 |
HashSet, ArrayList, LinkedList 클래스
HashSet 클래스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Set<String> set = new HashSet<String>();
set.add("one");
set.add("two");
set.add("three");
set.add("four");
System.out.println(set.add(new String("one"))); //에러: 중복을 허용하지 않음
System.out.println(set.size()); //4
System.out.println(set.contains("four")); //true
System.out.println(set.contains(new String("one"))); //true
set.remove("four");
set.remove(new String("one"));
System.out.println(set.size()); //2
set.clear();
System.out.println(set.size()); //0
ArrayList<E> 클래스
- List 인터페이스를 구현한 클래스
- 크기 조절이 가능한 배열로 구현
- 같은 자료가 중복될 수 있으며, 입력된 순서대로 관리됨
- 특정 위치의 자료를 참조하기 위해 첨자를 사용할 수 있음
Iterator<E> 인터페이스
- 컬렉션에 저장된 원소를 차례대로 다룰 수 있음
hasNext(),next()메소드 제공- HashSet, ArrayList, LinkedList 등에서 Iterator 객체를 리턴하는
iterator()메소드를 사용할 수 있음
1
2
3
4
List<String> list = new ArrayList<String>;
Iterator<String> it = list.iterator();
while (it.hasNext())
System.out.println(it.next());
LinkedList 클래스
- List 인터페이스를 구현한 클래스
- 스택 자료구조에서 필요한 메소드 제공
push(E),pop()
- Queue 인터페이스도 구현함
| 메소드 | 설명 |
|---|---|
| boolean offer(E) | 뒤에 원소를 추가함 (중복이어도 예외를 발생시키지 않음) |
| E poll() | 앞의 원소를 삭제하고 리턴함 (예외를 발생시키지 않음) |
| peek() | 앞의 원소를 리턴함 (예외를 발생시키지 않음) |
1
2
3
4
5
6
7
8
9
10
11
LinkedList<String> queue = new LinkedList<String>();
queue.offer("one");
queue.offer("two");
queue.offer("three");
queue.offer("four");
String s = queue.poll();
while (s != null) {
System.out.println(s);
s = queue.poll();
}
Map<K, V> 인터페이스
<key, value>로 이루어진 원소로 구성되는 컬렉션을 다루기 위한 인터페이스- key는 중복되지 않으며, 하나의 key에 하나의 value만 대응됨
- 원소들의 순서는 중요하지 않음
| 메소드 | 설명 |
|---|---|
| V put(K key V value) | 맵에 <키, 값> 매핑을 추가. 이미 키가 존재하면 값이 변경됨 |
| V get(Object key) | 맵에서 키와 매핑된 값을 리턴함. 없으면 null을 리턴 |
| V remove(Object key) | 맵에서 키와 매핑된 값을 제거하고 값을 리턴함. 없으면 null을 리턴 |
| boolean containsKey(Object key) | 지정된 키가 맵에 있으면 true를 리턴함 |
| Collection | 맵에 존재하는 값들로 구성된 컬렉션을 리턴함 |
| Set | 맵에 존재하는 키들로 구성된 컬렉션을 리턴함 |
HashMap 클래스
- 해싱을 이용하여 Map 인터페이스를 구현한 클래스
- 자료 탐색 방법이 ArrayList나 LinkedList 클래스와 다름
1
2
3
4
5
6
7
8
9
10
11
12
Map<String, Integer> lectures;
Map<String, Map> scores = new HashMap<>();
lectures = new HashMap<String, Integer>();
lectures.put("국어", 100);
lectures.put("영어", 95);
lectures.put("수학", 80);
score.put("영희", lectures);
System.out.println(scores.get("영희").get("국어"));
System.out.println(scores.get("영희").get("영어"));
System.out.println(scores.get("영희").get("수학"));
반복
외부 반복
- 컬렉션이나 배열의 원소를 다룰 때 원소의 반복 처리를 프로그램에서 명시적으로 제어하는 방식
- 원소를 프로그램에서 선언된 변수로 복사한 후 작업을 처리함
- for, 향상된 for, while, do-while, Iterator 등
1
2
3
4
5
6
7
8
9
10
List<String> names = Arrays.asList("Kim", "Lee", "Park");
for (String name: names) {
System.out.println(name);
}
Iterator<String> iterator = names.listIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
내부 반복
- 원소의 반복 처리를 컬렉션 또는 스트림과 같은 데이터 구조 내부에서 처리하는 방식
- 프로그램에서 스트림 API를 이용하여 반복 처리를 위임하고, 처리 코드만 람다식으로 제공함
- 코드가 간결해지며 가독성이 좋아짐
- 병렬 처리가 가능하며 성능 최적화에 유리
- forEach
- 함수형 인터페이스인 Consumer 객체를 인자로 받음
1
2
List<String> names = Arrays.asList("Kim", "Lee", "Park");
names.forEach(item -> System.out.println("내부 반복:" + item));
스트림
- 컬렉션이나 배열 원소의 시퀀스를 표현하고 효율적인 처리 방법을 제공하는 인터페이스
- 내부 반복과 함수형 프로그래밍 방식을 지원
- 멀티코어 CPU를 활용한 병렬처리 지원
- 관련 클래스와 인터페이스는
java.util.stream패키지에 있음 - 다양한 집합체 연산을 지원함(중간처리 연산과 최종처리 연산)
- 메소드 체이닝을 사용하여 스트림 연산을 파이프라인 형태로 연결할 수 있음
- 데이터 원본으로부터 일회용 스트림을 생성하며, 원본 데이터는 변경하지 않음
- 지연 평가(lazy evaluation)를 통해 연산을 최적화
숫자와 스트림
- 기본형 int, long, double형의 원소로 이루어진 데이터를 다루기 위해 IntStream, LongStream, DoubleStream 인터페이스를 사용
| 메소드 | 설명 |
|---|---|
| static IntStream range(int, int) | 첫 번째 int부터 두 번째 int - 1까지의 int형 스트림을 리턴함 |
| static IntStream rangeClosed(int, int) | 첫 번째 int부터 두 번째 int까지의 int형 스트림을 리턴함 |
| sum() | 모든 원소의 합을 리턴함 |
| average() | 모든 원소의 평균을 구함 |
| boolean containsKey(Object key) | 지정된 키가 맵에 있으면 true를 리턴함 |
| Collection | 맵에 존재하는 값들로 구성된 컬렉션을 리턴함 |
| Set | 맵에 존재하는 키들로 구성된 컬렉션을 리턴함 |
배열과 스트림
- Arrays 클래스에서 제공하는 stream 메소드를 사용하여 배열로부터 스트림을 생성할 수 있음
static <T> Stream<T> stream(T[])static IntStream stream(int[] array)static DoubleStream stream(double[] array)
1
2
3
String[] strArray = {"홍길동", "이순신", "김유신"};
Stream<String> strStream = Arrays.stream(strArray);
strStream.forEach(item -> System.out.println(item));
파일과 스트림
Files.lines(Path)메소드를 사용하여 텍스트 파일로부터 행 단위 문자열로 구성된 스트림을 생성할 수 있음
1
2
3
4
5
Path path = Paths.get("c:\\data\\data.txt");
Stream<String> fileStream = Files.lines(path);
fileStream.forEach(line -> System.out.println(line));
fileStream.close();
컬렉션과 스트림
- Collection 인터페이스에서
stream()과parallelStream()메소드를 디폴트 메소드로 제공parallelStream()는 병렬처리가 가능한 스트림을 리턴함- HashSet, ArrayList, LinkedList 객체 등으로부터 스트림을 생성할 때 사용
중간처리 연산
- 원본 스트림을 변환하거나 필터링하는 작업을 수행한 후 다음 단계 처리를 위해 새로운 스트림을 리턴하는 연산
- 중간 연산에서 생성된 스트림은 다음 연산으로 연결되어 파이프라인을 형성하며, 체인 형식으로 여러 번 호출할 수 있음
- 최종 연산과 함께 사용되어야 함
- 중간 연산들은 실제로 데이터를 처리하지 않고 연산의 파이프라인만 구성하며, 최종 연산이 호출되어야 비로소 전체 스트림 파이프라인이 실행됨
filter(),map(),sorted(),peek()등
필터링
- 원소들 중에서 중복을 제거하거나 특정 조건을 만족하는 원소만 추출하여 새로운 스트림을 생성하는 작업
distinct(): 중복을 제거하는 메소드filter(): 조건을 통해 걸러내는 메소드
매핑
- 원소들을 다른 원소로 변환하여 새로운 스트림을 생성하는 작업
map(): 원소들을 Stream<T>로 변환하는 메소드mapToInt(): 원소들을 IntStream으로 변환하는 메소드flatMap()과flatMapToInt()는 원소들을 변환한 후, 다시 하나의 스트림으로 합치는 메소드
정렬
- 원소들을 오름차순 또는 내림차순으로 정렬하여 새로운 스트림을 생성하는 작업
sorted()
루핑
- 원소들을 하나씩 순회하면서 반복적으로 처리하고 새로운 스트림을 생성하는 작업
peek(): 각 요소를 순회하면서 동작(람다식)을 수행peek()는 중간연산이고forEach()메소드는 종료연산
최종처리 연산 (종료연산)
- 최종적인 결과를 만들거나 동작을 수행하는 부분
- 스트림 연산 파이프라인에서 마지막에 한 번만 수행됨
forEach(),collect(),count(),anyMatch(),reduce()등
1
2
3
4
5
6
String[] words = Array.asList("apple", "banana", "cherry");
long count = words.stream() // 원본 스트림
.map(String::toUpperCase) // 중간 연산
.filter(word -> word.startsWith("A")) // 중간 연산
.count(); // 최종 연산
집계
- 원소들의 개수, 합계, 평균, 최대값, 최소값 등을 구하는 최종처리
count(),sum(),average(),max(),min()등
매칭
- 원소들이 특정 조건을 만족하는지 확인하는 최종처리
anyMatch(): 최소 하나의 원소가 조건을 만족하면 true를 반환allMatch(): 모든 원소가 조건을 만족하면 true를 반환noneMatch(): 모든 요소가 조건을 만족하지 못하면 true를 반환
수집
- 원소들을 필터링 또는 매핑한 후 최종적으로 새로운 컬렉션을 생성하는 종료 연산
collect()
This post is licensed under CC BY 4.0 by the author.