[Pandas] 데이터 분석하기
Pandas
Series, Dataframe과 같은 데이터 구조를 생성하고 변경할 수 있도록 도와주는 라이브러리
Array 계산에 특화된 NumPy를 기반으로 설계
Series
Data와 Index를 가지고 있다.
Numpy의 array는 명시적인 인덱스 없이 0부터 시작하는 인덱스 값을 가지지만 Series는 인덱스를 명시적으로 정할 수 있다.

Dataframe
여러 개의 Series가 모여서 행과 열을 이룬 데이터
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
population_dict = {
'korea': 5180,
'japan': 12718,
'china': 141500,
'usa': 32676
}
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 140925000,
'usa': 2041280000
}
population = pd.Series(population_dict)
gdp = pd.Series(gdp_dict)
country = pd.DataFrame({
'population': population,
'gdp': gdp
})
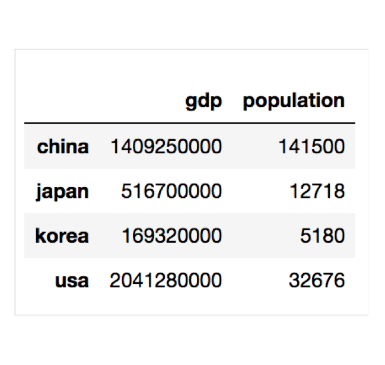
print(country.index)
#Index(['china', 'japan', 'korea', 'usa'], dtype='object')
print(country.columns)
#Index(['gdp', 'population'], dtype='object')
print(type(country['gdp']))
# pandas.core.series.Series
연산으로 검색하기
Series도 Numpy처럼 masking 연산(조건을 만족하는지에 따라 true/false로 마스킹) 사용이 가능하다.
1
2
3
4
5
6
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
df[“A”] < 0.5
# A열의 행이 0.5 미만이면 true, 이상이면 false

조건으로 검색하기
1
2
3
4
5
6
7
8
9
10
11
12
import numpy as np
import pandas as pd
# 첫 번째 방법 : A열과 B열 각각 마스킹 연산
df[(df["A"] < 0.5) & (df["B"] > 0.3)]
# 두 번째 방법 : query 메서드에 문자열로 조건을 전달
df.query("A < 0.5 and B > 0.3")
# 세 번째 방법 (데이터가 string인 경우) : 특정 문자열을 포함하는지 체크
df["Animal"].str.contains("Cat")
df.Animal.str.match("Cat")
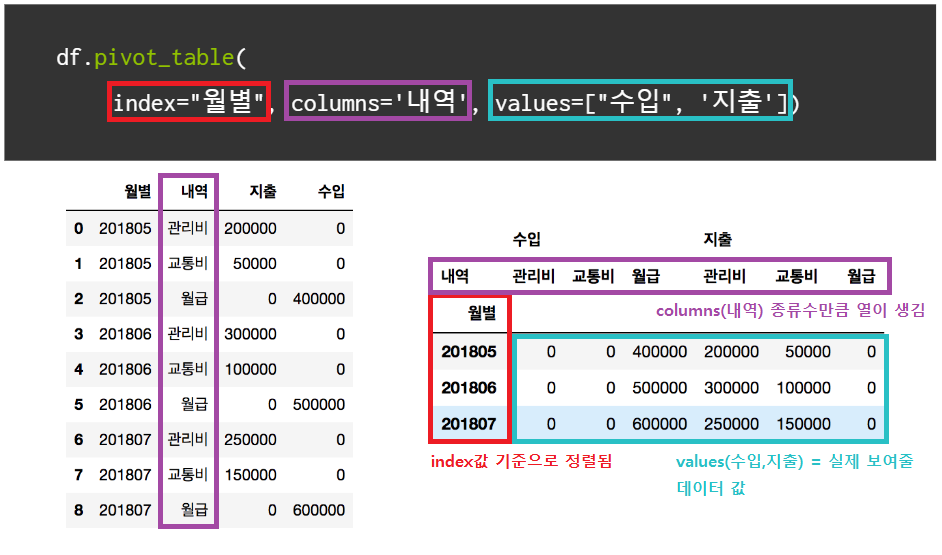
pivot_table
데이터에서 필요한 자료만 뽑아서 새롭게 요약, 분석 할 수 있는 기능
- index : 행 인덱스로 들어갈 key
- columns : 열 인덱스로 라벨링될 값
- values : 분석할 데이터
월별 수입/지출 내역 데이터 뽑기
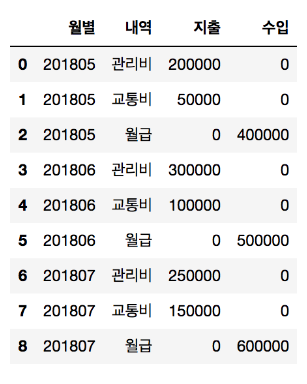
위와 같은 자료가 있을 때, 월별 수입과 지출에 대한 내역을 pivot_table로 뽑아보자.
1
df.pivot_table(index="월별", columns="내역", values=["수입", "지출"])
연습문제
피리 부는 사나이를 따라가는 아이들
피리부는 사나이가 마을의 어린이들과 쥐떼를 데리고 떠났어요!
csv 파일을 불러와 얻을 수 있는 데이터 프레임에서 일자별 남자 어린이와 여자 어린이의 평균 연령을 pivot_table로 출력하세요.
| 컬럼 | 의미 |
|---|---|
| 일차 | 쥐는 “Rat”, 아이는 “Child”로 구분됨 |
| 이름 | 쥐 또는 아이의 이름 |
| 나이 | 쥐 또는 아이의 나이 |
| 성별 | 쥐 또는 아이의 성별 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import pandas as pd
import numpy as np
def main():
# 파일을 읽어서 코드를 작성해보세요
# 경로: "./data/the_pied_piper_of_hamelin.csv"
df = pd.read_csv("./data/the_pied_piper_of_hamelin.csv")
# Child(아이들)만 마스킹 연산으로 뽑아내기
children = df[df["구분"] == "Child"]
# index="일차" : 일차를 index로 맞춤
# columns="성별" : 성별 값들로 열을 나눔
# values="나이" : 나이 값을 분석
# aggfunc=np.mean : 평균 데이터로 묶음
print(children.pivot_table(index="일차", columns="성별", values="나이", aggfunc=np.mean))
if __name__ == "__main__":
main()
This post is licensed under CC BY 4.0 by the author.